PaperGuidelines for Evaluating Student Outcomes
VIII. AnalysisThe credibility of your study will be bolstered through a sound analysis. The analysis tools that you use in your study need to be consistent with your study design, the type of outcome data that you are including, and the levels of data (student, teacher, etc.) that are represented in your study. Ultimately, the analysis should allow you to determine whether the student outcomes under study have changed, and whether any change is likely to be a result of the LSC. It is important that you make a case for the appropriateness of your analysis based on these concerns. For a quantitative study, regardless of whether your outcomes are measured on continuous or categorical metrics, your analysis will include two main phases: describing your data and statistical testing. Issues involved in each of these, as well as disaggregating data by demographic subgroups and analysis of qualitative data, are discussed in the following sections. A. Descriptive Statistics Descriptive statistics are used to provide simple summaries of your data. They form the basis of most quantitative analyses of data and are frequently illustrated with simple graphic displays. In general, you want to report descriptive information about the students in your study (race/ethnicity, gender, etc.) both overall and for each treatment group. You also might want to disaggregate your outcome measures by race/ethnicity, gender, or some other demographic characteristic of interest to look for differential performance among certain sub-populations (see section C below). The appropriate method for describing your data depends solely on whether the data are measured on a categorical scale (e.g., demographics, attainment of standard) or continuous scale (e.g., percentile score). If the data are categorical, it is typical to report the overall number of students and the percent of students in each category. For example, you may choose to present the race/ethnicity of students in your treatment and comparison groups as follows: Percent of students
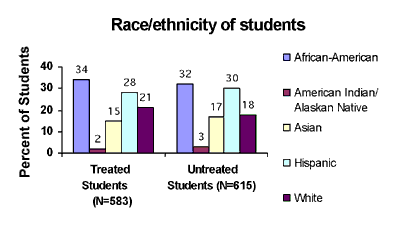
Another option would be to present the data using a bar chart or histogram:
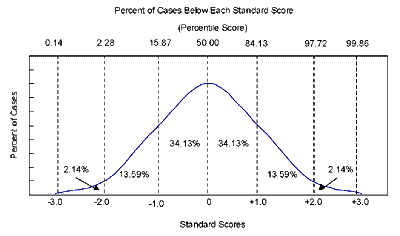
When presenting continuous data, it is appropriate to report measures of central tendency and dispersion as well as the number of cases in each group. In most cases, you will want to use the mean as your measure of central tendency, rather than the median or the mode. While the mean provides a considerable amount of information about your data, it is generally not a sufficient descriptor. You also need to indicate how the data are dispersed around the mean. The most useful estimate of dispersion is the standard deviation. The formula for the standard deviation is based on the distance that each score is from the mean, and it is usually calculated using statistical software such as SPSS or SAS. If your scores have a normal distribution-a bell-shaped curve or something close to it-the following statements can be made:
Classic Bell-shaped Curve
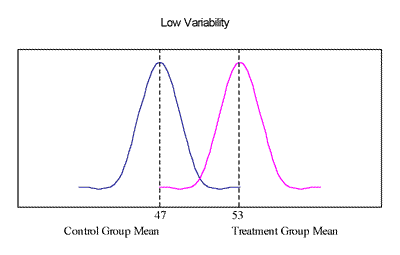
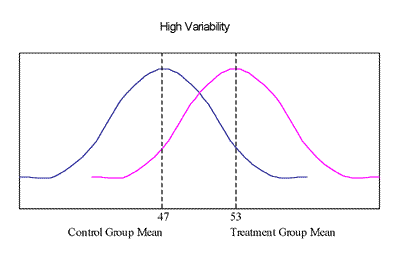
B. Inferential Statistics Inferential statistics are used to test whether the data you obtained from your sample reflect the results that would be obtained if you used the entire population. Inferential statistics also are used when you want to show that the difference between your treatment and control groups is dependable and not the result of chance. Common inferential statistical procedures are the t-test, chi-square test, analysis of variance (ANOVA), regression, and hierarchical linear modeling (HLM). For example, you may want to compare test scores of your treatment group (students whose teachers had participated in the LSC project) with your control group (students whose teachers did not participate). As a part of your analysis, you have already calculated the means for the two groups. Let's say that the mean for the treatment group is 53, and the mean for the control group is 47. Since the means are different by 6 points, it might appear that the two groups are different, but it is not quite so simple. The means alone do not give enough information; you also need to know about the dispersion around the mean. This concept can be illustrated by using two extreme examples. Notice that in both examples the mean for the control group is 47, and the mean for the treatment group is 53. However, in Example A, the scores of each of the two groups (treatment and control) vary a great deal, and the scores for the two groups overlap a great deal. Example B provides quite a contrasting picture in which the scores within the treatment and control groups show little variation, and there is little overlap between the two groups. The two groups appear to be most distinct in Example B. Example A:
Example B:
There are several factors that influence the selection of the appropriate statistical test. Most important are the metrics upon which the outcomes are measured (continuous or categorical) and the design of your research study. However, this is not all you must consider in this decision. All statistical tests are based upon assumptions about the data. For example, the t-test assumes that your data are normally distributed, and the ANOVA requires homogeneity of error variances. If a statistical test's assumptions are not met, the test could give spurious results and another statistical procedure should be considered (e.g., rank-ordered comparisons). For this reason, it is often advisable that you seek the help of a knowledgeable statistical consultant for the analysis of your data. Because statistical tests are sensitive to the number of cases in your groups, tests involving a large number of cases often detect as statistically significant differences that are too small to be of practical significance. Thus, it is desirable to include a measure of magnitude of the difference between your groups-commonly referred to as the effect size. While the statistical test can tell you if the difference between your groups is significant (likely real rather than due to chance), the effect size helps you decide if the difference is substantial. When comparing means, the effect size is the number of standard deviations between the means of the two groups (i.e., the difference between the means divided by the overall standard deviation). Typically, an effect size of 0.2 is considered small, 0.5 medium, and 0.8 large. C. Disaggregating Data by Demographic Subgroups You might find that the treatment group as a whole does significantly better on the post-test than the control group. However, some students may be experiencing a greater effect than others. Conducting separate analyses for various demographic subgroups will show if there are patterns in the outcomes; this process is called disaggregating the data. For example, you might find that boys are scoring considerably higher than girls and subsequently would want to explore the reason for the differences, so you could take appropriate steps to ensure that all students are having an opportunity to learn important science/mathematics. Common subgroups for disaggregating the data are gender and race/ethnicity. Other subgroups that you might consider are class size or number of students in poverty as determined by their participation in the free and reduced-priced lunch program (sometimes easier to do at the elementary than secondary levels). One issue in doing this type of analysis is that you must have enough students in each group. Indeed, a rule of thumb is that you should have a minimum of 20 cases in each subgroup for analytic purposes. D. Qualitative Analyses Frequently it is useful to combine quantitative analysis with qualitative analysis. The former provides an overview of success as determined by outcomes that lend themselves to direct measurement and numerical summarization; the latter provides information on outcomes that are best addressed through rich description. For qualitative analyses, it is important to provide full descriptions of how the data were collected, how the data were analyzed, and how conclusions were drawn from the analysis. Depending on the number of cases you include, either individual case studies or an integrative analysis across data sources might be reported. If the latter approach is chosen, examples from the data should be provided to support your methods and your conclusions. Such examples will both enable your audiences to judge the credibility of your conclusions and gain a deeper understanding of the context of the effects observed.
|
||||||||||||||||||||||||||||||||||||||||||||||